Deploying your Astro blog
Keep your Astro source private and publish only the static build
GitHub Pages for private respositories is not supported on GitHub Free (read here) and I didn’t like the idea of making the whole blog’s source code and post drafts publicly available. So I had to come up with a solution.
NOTE
I’m aware that Cloudfare Pages it’s free, faster than GitHub Pages, and supports private repos. But I also had the comments section tied to the public repo so. Maybe next time…
The idea is simply using a two-repository strategy:
- Private repo - Where we keep our source code with drafts, work-in-progress posts, and all our Astro source files.
- Public repo - Just the contents of the
dist/folder, for GitHub Pages deployment.
Configuring the Deployment Target
By deployment target, I mean the public repo from where we will will serve the site to the world, using GitHub Pages.
NOTE
Remember, our private repo is where we write posts, keep drafts, and build the Astro project. The public repo is just where we push the final static output.
In our public repo, we have to configure a publishing source for GitHub Pages. There are a couple of options here:
- To publish when changes are pushed to a specific branch.
- Or you can write a GitHub Actions workflow to publish your site.
We’ll be using the first option; just click on the Settings tab of your repo, and once there, find the Pages slot in the left sidebar. Mine looked like this:
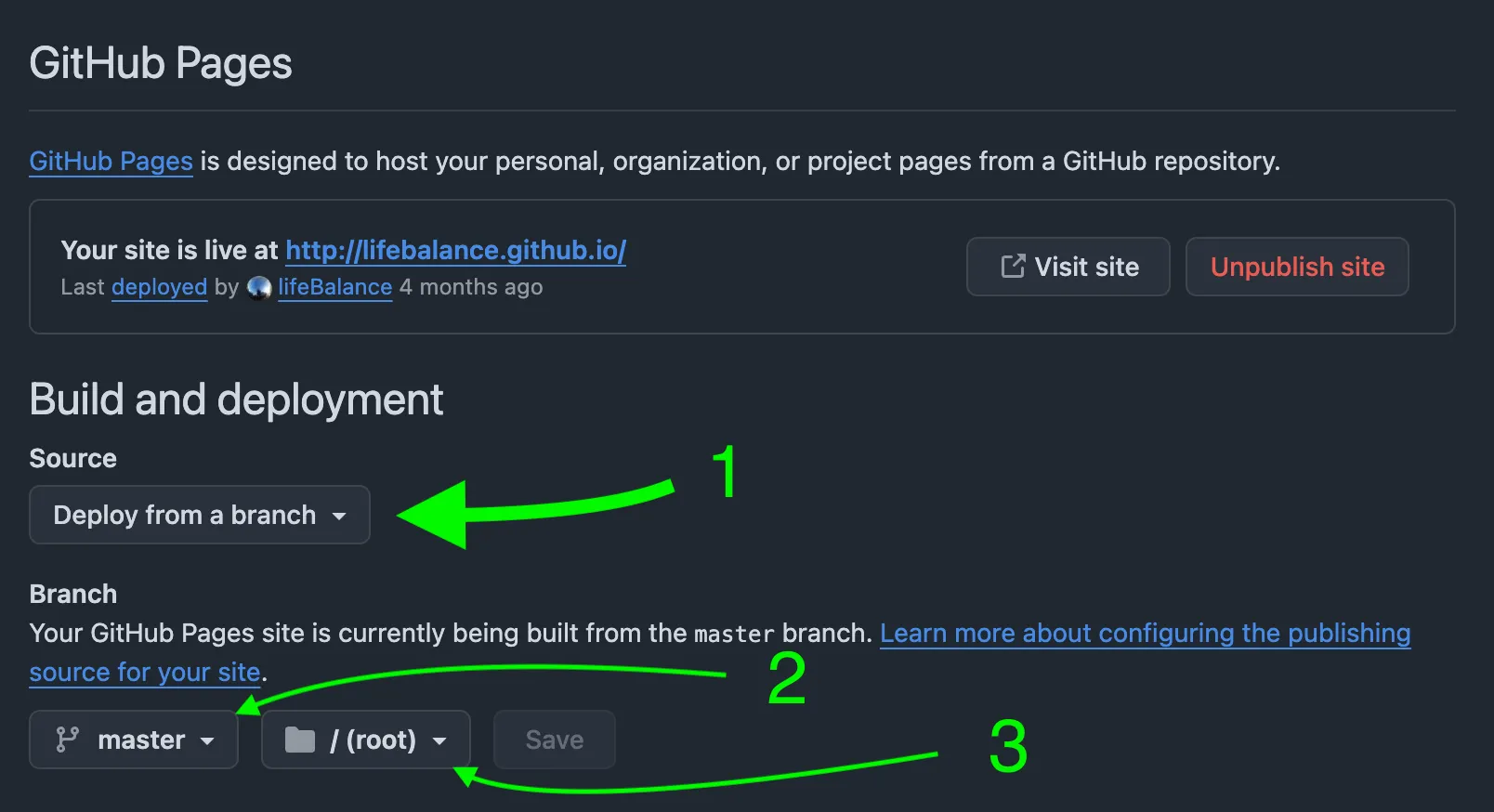
What this means is that whenever we push changes to the master branch (root folder /), our GitHub pages will be published.
For Astro Users
Before building our site, we need to tell Astro the final public URL where our site will be published. This is controlled by two settings in astro.config.ts:
- site is the domain where we will serve the site.
- base is the path under that domain where your site will live.
Since we will be serving the page from the URL of the public repo, we need to add it to our astro.config.ts:
export default defineConfig({ site: 'https://<username>.github.io', base: '/', // more stuff...})If your public repo is the special GitHub Pages repo named <username>.github.io, then the site is served from the root:
https://<username>.github.io/.
TIP
In my case, since it was my personal page, I used the https://<username>.github.io URL. But it doesn’t have to be, any public repo URL will do, e.g. https://github.com/<username>/<repo-name>.
But if you’re publishing to a repo named foo, then you should use something like:
site: 'https://github.com'base: 'foo'
TLDR
Just three steps:
- Build your project; from the private repo run:
npm run build- Copy the contents of the
distfolder, from the private repo to the public repo:
rsync -a --delete --exclude '.git' dist/ ../my-blog-public/- Move to the public repo, and push changes:
cd ../my-blog-publicgit add -Agit commit -m 'new build'git push1. Creating the Build
Not much to say here, whenever you add a new post, and are ready to publish, you need to build right? Let’s assume you have the following build script in the package.json of your private repo:
"build": "astro build"We just have to change to the root of your private repo, and run:
npm run buildIn the case of an Astro project, we should end up with a dist folder containing the artifacts of our build.
2. Copy the Build to the Public Repo
Now the goal is to move the contents of the dist folder (not the folder itself, but its contents), to the root of our public repo. :
rsync -a --delete --exclude '.git' dist/ ../my-blog-public/Let’s go over the flags:
dist/with trailing slash copies the contents of dist, not the folder itself.--deleteremoves stale files from the public repo.--exclude '.git'preserves the public repo Git metadata.- It copies hidden files like
.nojekyll.
TIP
In Astro, dist is the default build folder; but if you’re using another one, or not even using Astro, feel free to use whatever folder you need to.
The command above assumes that you have cloned your public repo to the parent folder of the private repo. Check the following folder structure:
parent-folder/ ├── my-private-repo/ # 👈 We're working here. │ ├── src/ │ ├── content/ │ └── dist/ └── my-blog-public/ # 👈 Make sure you have cloned your public repo. └── .git/3. Pushing Changes to the Public Repo
Push the changes to your GitHub public remote:
cd ../my-blog-publicgit add -A # Stage the changesgit commit -m "New build" # Commitgit push # PushThat should be enough you have your page live after a few seconds.
GitHub Actions
Ok, now that we’re familiar with the steps to publish our site manually, let’s see how we can do the same with a GitHub Actions workflow.
NOTE
Remember, the idea is quite simple: keep the repo with the source code and posts private, and push the build to a public one.
In the private repo, if I go to Settings > Pages, I’ll see a warning:
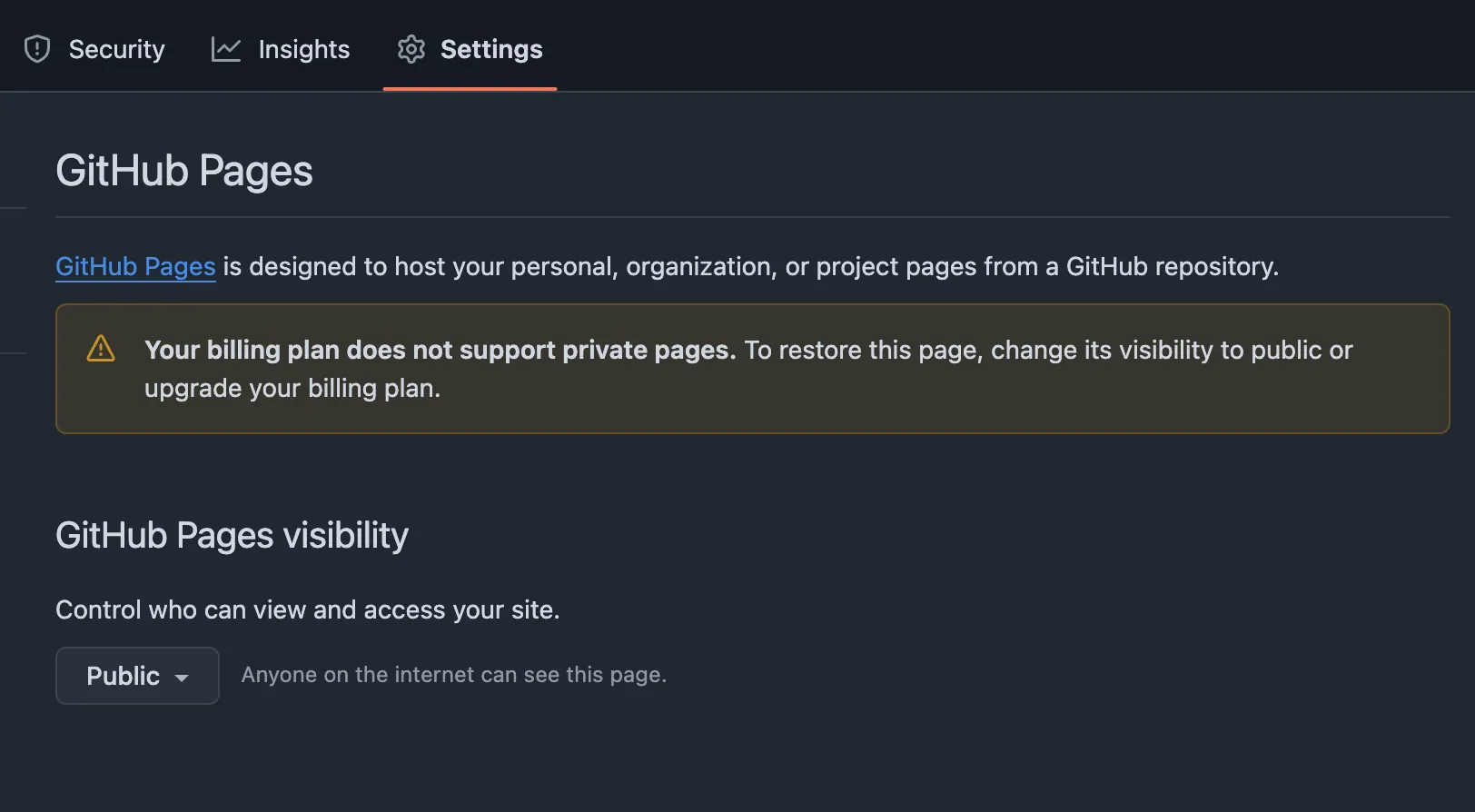
That’s the root of the problem: with a free account, I can’t have GitHub Pages in a private repo.
Creating a PAT
Before start writing the action, we need to create a GitHub Personal Access Token tied to the user that has push access to the public repo (myself).
In order to do that we have to click on our user logo (upper right corner), and once the sidebar opens up, click on Settings → Developer Settings → Personal access tokens. I selected Tokens (classic), then Generate new token, and Generate new token (classic).
NOTE
Make sure you do not over-scope the token. For your use, just public_repo is enough to gives the token access to public repositories, which is enough for your workflow to push the built dist/ files to.
Give it a descriptive description (under Note); I named mine Deploy code-blue to lifeBalance.github.io. Once the token has been generated, you are redirected to a new page; you should copy the token name GH_PAGES_TOKEN.
WARNING
Make sure to copy your token now as you will not be able to see it again.
If for some reason you didn’t copy the token, just regenerate it again, no big deal.
Using the PAT
Now we need to add the PAT as a secret (e.g., GH_PAGES_TOKEN) in the private repo:
- In our private repo, we go to
Settings → Secrets and variables → Actions - Click New repository secret.
- Name it
GH_PAGES_TOKEN(or whatever you name it in the*.ymlfile). - Paste your copied PAT.
That’s it — now your GitHub Actions workflow will automatically have access to it through ${{ secrets.GH_PAGES_TOKEN }} — no manual shell exports needed ever again.
The Workflow
Create a .github/workflows/deploy.yml in the private repo:
name: Deploy to GitHub Pages
on: push: branches: [main] workflow_dispatch: # Manual trigger for actions
jobs: deploy: runs-on: ubuntu-latest steps: - uses: actions/checkout@v3
- name: Install dependencies run: npm ci
- name: Build site run: npm run build
- name: Add .nojekyll file run: echo > dist/.nojekyll # Ensures GitHub Pages ignores Jekyll processing
- name: Deploy to GitHub Pages env: GH_PAGES_TOKEN: ${{ secrets.GH_PAGES_TOKEN }} run: | TEMP_DIR=$(mktemp -d) cp -r dist/. "$TEMP_DIR" cd "$TEMP_DIR" git init git config user.name "GitHub Actions" git config user.email "actions@github.com" git remote add origin https://$GH_PAGES_TOKEN@github.com/lifeBalance/lifeBalance.github.io.git git checkout -b master # Use 'master' instead of 'main' for GitHub Pages default branch git add . git commit -m "Automated deploy" git push -f origin master # Push to master branchSwitching Workflows
If your GitHub Pro subscription expires and you can no longer publish GitHub Pages from a private repo, you do not need to delete your old GitHub Pages workflow. In my case, I kept .github/workflows/astro.yml around and disabled it.
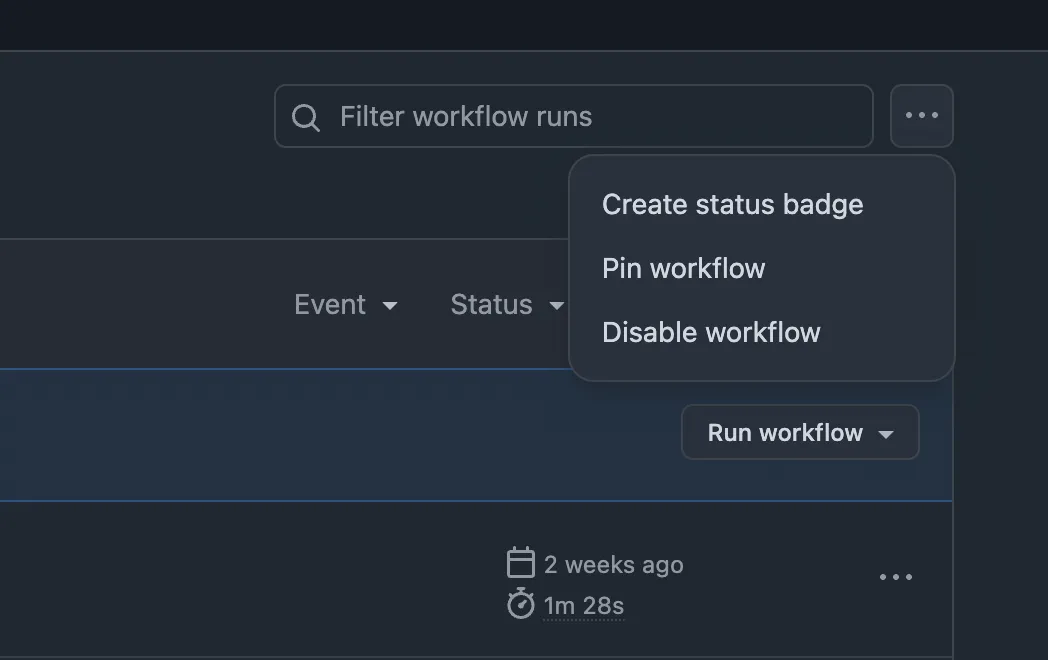
- Go to the Actions tab.
- Find the Deploy Astro site to Pages workflow. That is the workflow name from
astro.yml. - Open any previous run of that workflow.
- Click the
•••menu in the top-right corner. - Click Disable workflow.
IMPORTANT
This only disables astro.yml. It does not affect deploy.yml. The file stays in the repo, but GitHub will not run it unless you enable it again.
If you later re-enable GitHub Pro and want to deploy directly from the private repo again:
- Disable
deploy.yml, the workflow that pushes the build to the public repo. - Re-enable
astro.yml. - In the private repo, configure GitHub Pages to use GitHub Actions as the source.