Functional programming in TypeScript
Part 1 - Introduction and Function Composition
Functional programming is a programming paradigm, which allows us to write our programs in a declarative and composable way by combining functions.
Functional programming in TypeScript?
Functional programming is language agnostic, meaning that we can apply it using almost any language. The only requirement is that the language treats functions as first-class citizens, which means that we can:
- Assign functions to variables.
- Pass functions as arguments to other functions.
- Use functions as return values from other functions.
All of the above is doable in TypeScript, which makes it a suitable choice to write code in the FP paradigm.
NOTE
Pure functional programming is a somehow more strict paradigm, and the exact difference between pure and impure functional programming is a matter of controversy. In fact, the earliest programming languages cited as being functional, IPL and Lisp, are both impure functional languages. Some examples of pure functional languages are Haskell and PureScript.
There are several libraries such as ramda or fp-ts, that include features to allow us to write in a more pure functional style. In this series of articles, we won’t be using any of these, just vanilla TS.
But what is Functional Programming about?
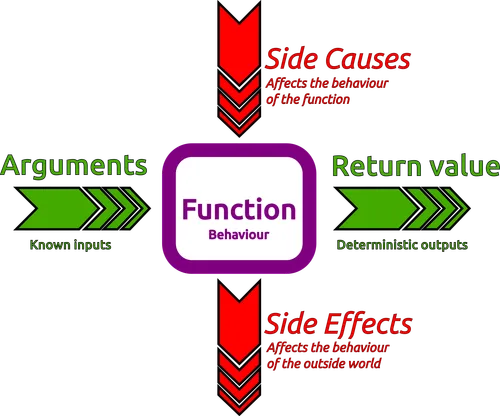
FP is about taking some input, and process it by using a chain of transformations (each transformations is accomplished by a function). When each of these functions is called with some given arguments, it will always return the same result (pure function).
In constrast, an impure function, like the ones we use in imperative programming, can have side effects (such as modifying the program’s state or taking input from a user). Side effects are considered undesirable in pure functional programming because they make functions less predictable and harder to test.
NOTE
But at some point, our application will have to interact with the outside world (get user input), how does FP deal with that? FP relegates dealing with side effects to a thin layer outside our application.
Some defining features of FP are:
- Functions are at the center of the paradigm. We end up with a bunch of reusable units of code, which leads to having to write less code to achive the same results.
- These functions are quite deterministic, meaning, given a given input, they always return the same output, regardless of the program’s state.
- Easy to test code: As a result, when writing tests for the functions, we don’t have to worry about program’s state.
- Easier to debug: FP aims to minimize or isolate side effects to make code more predictable, testable, and easier to debug.
- We’ll see that
fororwhileloops are not used in FP; in these scenarios we use recursion.
As with any other approach, it will take time to become comfortable using it. As a result, noticing its benefits will take some time.
Pure Functions
A pure function has the following characteristics:
- It’s deterministic, meaning that given the same input (given in the arguments), the function always returns the same output. That implies that the function shouldn’t be affected by the state of the program (no side causes), only by its input.
- A pure function has no side effects, meaning that calling such a function should not mutate the state of the program.
In FP, we don’t use variables only constants. Each transformation (function call) returns a new value, which is assigned to a constant. This constant can be used as input (argument) in the next transformation.
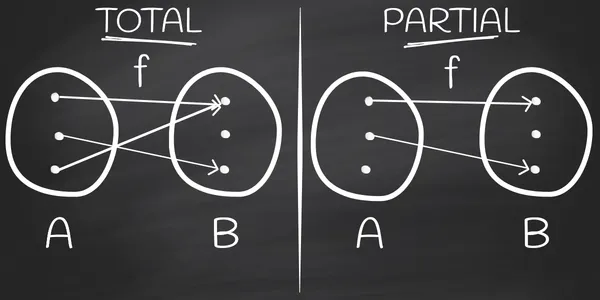
Total vs Partial Functions
A total function is a function that is defined for all possible inputs in its domain. This means that for every input value in the domain, the function will produce a valid output. For example:
function add(a: number, b: number): number { return a + b}A partial function is a function that is defined for only a subset of inputs in its domain. For some inputs, the function may not produce a valid output or may result in an error. For example:
function divide(a: number, b: number): number { if (b === 0) { throw new Error('Division by zero is not allowed') } return a / b}So the main difference is that total functions map all of its inputs to some output value, whereas partial functions map only a subset of its inputs to some output:
IMPORTANT
Deterministic also means that a given input value can be mapped to one and only one output value. If an input value could result in one of several output values, that’s not very deterministic, ain’t it?
Key Differences Between Total and Partial Functions
| Aspect | Total Function | Partial Function |
|---|---|---|
| Definition | Defined for all inputs in its domain. | Defined for only a subset of inputs. |
| Behavior | Always produces a valid output. | May fail or throw errors for some inputs. |
| Input Validation | No input validation is needed. | Input validation is often required. |
Why Total Functions Are Preferred in Functional Programming
-
Predictability: Total functions are easier to reason about because they are guaranteed to work for all inputs.
-
No Runtime Errors: Total functions eliminate the risk of runtime errors caused by invalid inputs.
-
Composability: Total functions can be composed more easily because they always produce valid outputs, which can be passed as inputs to other functions.
-
Immutability: Total functions align with the principles of functional programming, where functions are deterministic and side-effect-free.
How to Handle Partial Functions in FP
In functional programming, partial functions are often avoided or handled explicitly using techniques like:
- Option Types (e.g.,
MaybeorOption): Wrap the result in a type that explicitly represents the possibility of failure. For example:
function safeDivide(a: number, b: number): number | null { return b === 0 ? null : a / b}- Validation: Validate inputs before calling the function to ensure they are within the valid subset.
function divide(a: number, b: number): number { if (b === 0) { throw new Error('Division by zero is not allowed') } return a / b}Function Composition
Most of what we do in FP is composing functions, which consists in combining two or more functions to produce a new function; The output of one function becomes the input of the next one. Function composition allows us to build complex operations by combining smaller, reusable functions.
For example, imagine we have the function increment:
type Increment = (x: number) => number
const increment = (x: number): number => x + 1And also the function stringify:
type Stringify = (x: number) => string
const stringify: Stringify = (x) => x.toString()Using function composition we can define a higher-order function named incrementAndStringify, where we connect the output tof increment to the input of stringify:
type IncrementAndStringify = (x: number) => stringconst incrementAndStringify: IncrementAndStringify = (x) => stringify(increment(x))
const result: string = incrementAndStringify(1)console.log(result) // "2"NOTE
Function composition is closely related to the property of referential transparency. A piece of code is referentially transparent if you can replace a function call with its result without changing the behavior of the program. For example:
const stringify = (x: number): string => x.toString()
const add = (a: number, b: number): number => a + b
const result = stringify(add(2, 3))const result2 = stringify(5) // We can replace add(2, 3) with 5A Step Up
In the previous section, we were composing functions by hardcoding their names into the composed version. It would be nicer if we could create a third function, which takes two functions, and return their composition:
type Increment = (x: number) => numberconst increment: Increment = (x) => x + 1
type Stringify = (x: number) => stringconst stringify: Stringify = (x) => x.toString()
type Compose = ( f: (x: number) => string, g: (x: number) => number) => (x: number) => string
const compose: Compose = (f, g) => x => f(g(x))
const incrementAndStringify = compose(stringify, increment)console.log(incrementAndStringify(33)) // "34"Adding Generic Types
It would be even nicer, if we could define our compose function so that it’s not limited to the types string and number. Check this out:
type Increment = (x: number) => numberconst increment: Increment = (x) => x + 1
type Stringify = (x: number) => stringconst stringify: Stringify = (x) => x.toString()
type IncrementAndStringify = (x: number) => string
type Compose = <T, U>( f: (x: T) => U, g: (x: T) => T) => (x: T) => U
const compose: Compose = (f, g) => x => f(g(x))
const incrementAndStringify: IncrementAndStringify = compose(stringify, increment)console.log(incrementAndStringify(41)) // "42"In the code above we are using two generics that allow us to replace T and U by any types. That way we can compose any two functions with different type signatures. In the way we defined the compose function above, we have only two constraints:
- The type of input of
g,f, and ourcomposefunction is the same. - The type of output of
fand ourcomposefunction is the same.
Using function composition allows us to reuse a lot of small functions by composing them in different ways, to achieve different results. Testing each of these functions is easy.
A Generic compose Function
We could take it a step further, and define a super generic compose function, that could take any two functions, no matter their signature:
type Compose = <A, B, C>( f: (x: B) => C, g: (x: A) => B) => (x: A) => C
const compose: Compose = (f, g) => x => f(g(x))
const incrementAndStringify: IncrementAndStringify = compose(stringify, increment)console.log(incrementAndStringify(41)) // "42"Here, we define a generic compose function compose with three generic types:
A: The type of input tog(the first function in the composition), and to thecomposefunction itself.B: The type of input tof, and the output fromg.C: The type of output fromf, and the output ofcompose(the final result).